AI

Join 500+ brands growing with Passionfruit!
TL;DR - Best model by job:
• Coding & complex reasoning: GPT-5 / GPT-5 Pro
• General chat at lower cost: 4o
• Math/logic with tools: o3
• Docs/data analysis & long context: GPT-5
• Lowest cost at scale: GPT-5 mini / API mix
• Automation & workflows: ChatGPT Agent
(Benchmarks, pricing, and step-by-step picks below.)
On August 7, 2025, OpenAI has released ChatGPT 5. With legacy models like GPT-4o being officially retired and new specialized versions like GPT-5 Pro emerging, how do you navigate this new landscape?
This article provides the definitive guide to OpenAI's 2025 lineup. We'll benchmark the standard ChatGPT 5, the powerhouse GPT-5 Pro, the new ChatGPT Agent capabilities, and the specialized Deep Research mode against their predecessors, OpenAI o3 and GPT-4o, to help you choose the perfect tool.
Which OpenAI Model Delivers the Best Performance, and How Does ChatGPT 5 Redefine the Lineup?
ChatGPT 5 represents a fundamental shift in how OpenAI structures its AI offerings. Rather than requiring users to manually select between different models for different tasks, the new unified ChatGPT 5 system automatically switches between fast and deep thinking modes based on your needs.
The key innovation lies in what OpenAI calls the "real-time router" - an intelligent system that analyzes conversation type, complexity, tool needs, and user intent to determine whether to use the quick-response model or engage the deeper "GPT-5 thinking" mode. According to OpenAI's technical documentation, this router is continuously trained on real signals including user model switches, preference rates, and measured correctness.
GPT-5 vs GPT-4 Differences - Quick Table (2025)
GPT-5 changes everyday outcomes: higher reasoning accuracy, stronger coding/math, and fewer tokens for the same work. Here’s what improves and where you feel it.
Area | GPT-4o / o3 | GPT-5 / GPT-5 Pro | What it means |
Science (GPQA Diamond) | o3: 83.3%, 4o: 70.1% | GPT-5: 87.3%, GPT-5 Pro: 89.4% | Fewer logic errors on PhD-level questions |
Coding (SWE-bench Verified) | o3: 69.1%, 4o: 30.8% | GPT-5 (thinking): 74.9% | More real GitHub issues solved |
Math (HMMT) | o3: 93.3% | GPT-5 no tools: 93.3%, GPT-5: 96.7%, GPT-5 Pro: 100% | Proof-level reliability |
Industry tasks (avg.) | o3 avg: 67.7%, 4o avg: 44.1% | GPT-5 avg (thinking): 80.1% | Better outcomes across domains |
Token efficiency (effort tokens) | Medium task: ~7,000 | Medium task: ~4,000 | Same answer, fewer tokens |
The New Model Hierarchy
Table 1: OpenAI's 2025 Model Lineup
Model | Purpose | Availability | Key Strength |
ChatGPT 5 (Standard) | General-purpose AI with automatic mode switching | All users | Unified system that adapts to query complexity |
GPT-5 Thinking | Deep reasoning mode within ChatGPT 5 | Automatic activation | Extended reasoning for complex problems |
GPT-5 Pro | Maximum performance variant | Pro/Team subscribers | Highest accuracy on challenging tasks |
GPT-5 mini | Lightweight fallback model | Free tier overflow | Fast responses when limits reached |
ChatGPT Agent | Task automation and workflow execution | Plus/Pro/Team | Agentic capabilities with tool coordination |
The unified approach means that when you type a query into ChatGPT, the system automatically determines whether to provide a quick response or engage deeper reasoning. This eliminates the cognitive load of model selection while ensuring optimal performance for each query type.
How Does the New ChatGPT 5 Perform on Academic Science Benchmarks?
ChatGPT 5 GPQA Science Performance
The Graduate-Level Science Questions (GPQA) benchmark tests PhD-level understanding across multiple scientific disciplines. This evaluation reveals the dramatic improvements in ChatGPT 5's scientific reasoning capabilities.
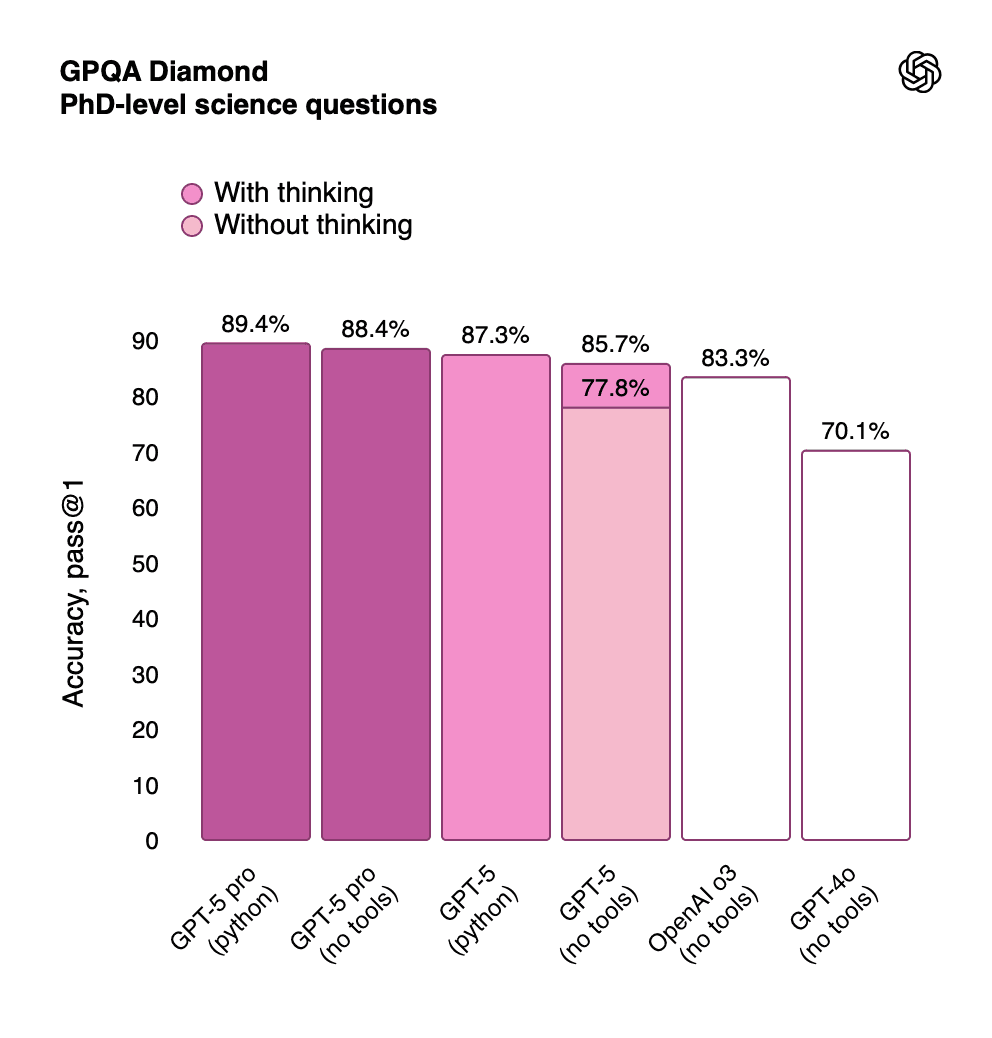
ChatGPT 5 demonstrates remarkable performance on the GPQA Diamond benchmark, achieving:
GPT-5 Pro (with Python): 89.4% accuracy
GPT-5 (with Python): 87.3% accuracy
OpenAI o3: 83.3% accuracy
GPT-4o: 70.1% accuracy
The introduction of thinking mode provides a substantial boost, with GPT-5's accuracy jumping from 77.8% to 85.7% when reasoning is engaged. This represents a fundamental improvement in the model's ability to tackle complex scientific problems that require multi-step reasoning and deep domain knowledge.
LiveCodeBench Competitive Programming with ChatGPT 5
GPT-5 leads SWE-bench Verified at 74.9%, ahead of o3 69.1%, 4o 30.8%. For a broader perspective on AI performance across multiple models, the Snorkel AI leaderboard provides a dynamic ranking of state-of-the-art systems and their benchmark results, offering insights into how GPT-5 compares in the wider AI landscape.
The SWE-bench Verified benchmark measures the ability to solve real-world GitHub issues.

Table 2: Software Engineering Performance Comparison
Model | With Thinking | Without Thinking | Improvement |
GPT-5 | 74.9% | 52.8% | +41.9% |
OpenAI o3 | 69.1% | N/A | N/A |
GPT-4o | 30.8% | N/A | N/A |
ChatGPT 5's coding prowess extends beyond simple problem-solving. According to OpenAI's developer documentation, the model shows particular improvements in:
Complex front-end generation with aesthetic sensibility
Debugging larger repositories
Creating responsive websites and applications in a single prompt
Understanding design principles like spacing, typography, and white space
How Do the New OpenAI Models Compare on Mathematical Reasoning, and What is the Role of ChatGPT 5?
ChatGPT 5 USAMO & AIME Mathematical Olympiad Performance
Mathematical reasoning represents one of the most significant leaps forward in ChatGPT 5's capabilities. The model's performance on competition mathematics benchmarks demonstrates expert-level problem-solving abilities.
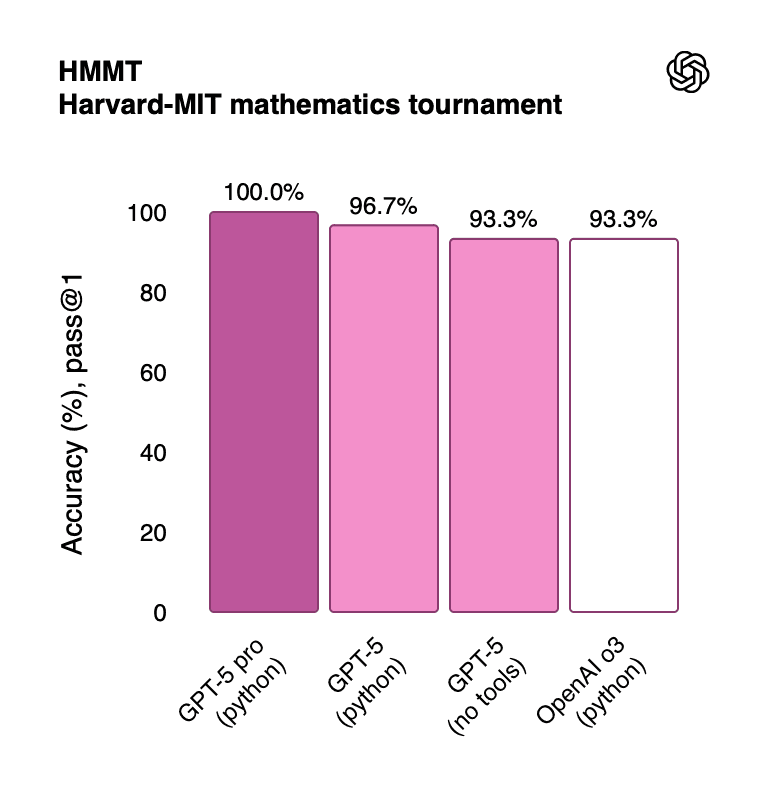
The Harvard-MIT Mathematics Tournament (HMMT) results show near-perfect performance:
GPT-5 Pro (with Python): 100% accuracy
GPT-5 (with Python): 96.7% accuracy
GPT-5 (no tools): 93.3% accuracy
OpenAI o3: 93.3% accuracy
ChatGPT 5 HMMT Competitive Mathematics Results
The breakthrough in mathematical capabilities extends to expert-level challenges. On FrontierMath, which tests the boundaries of mathematical reasoning, ChatGPT 5 achieves unprecedented results.
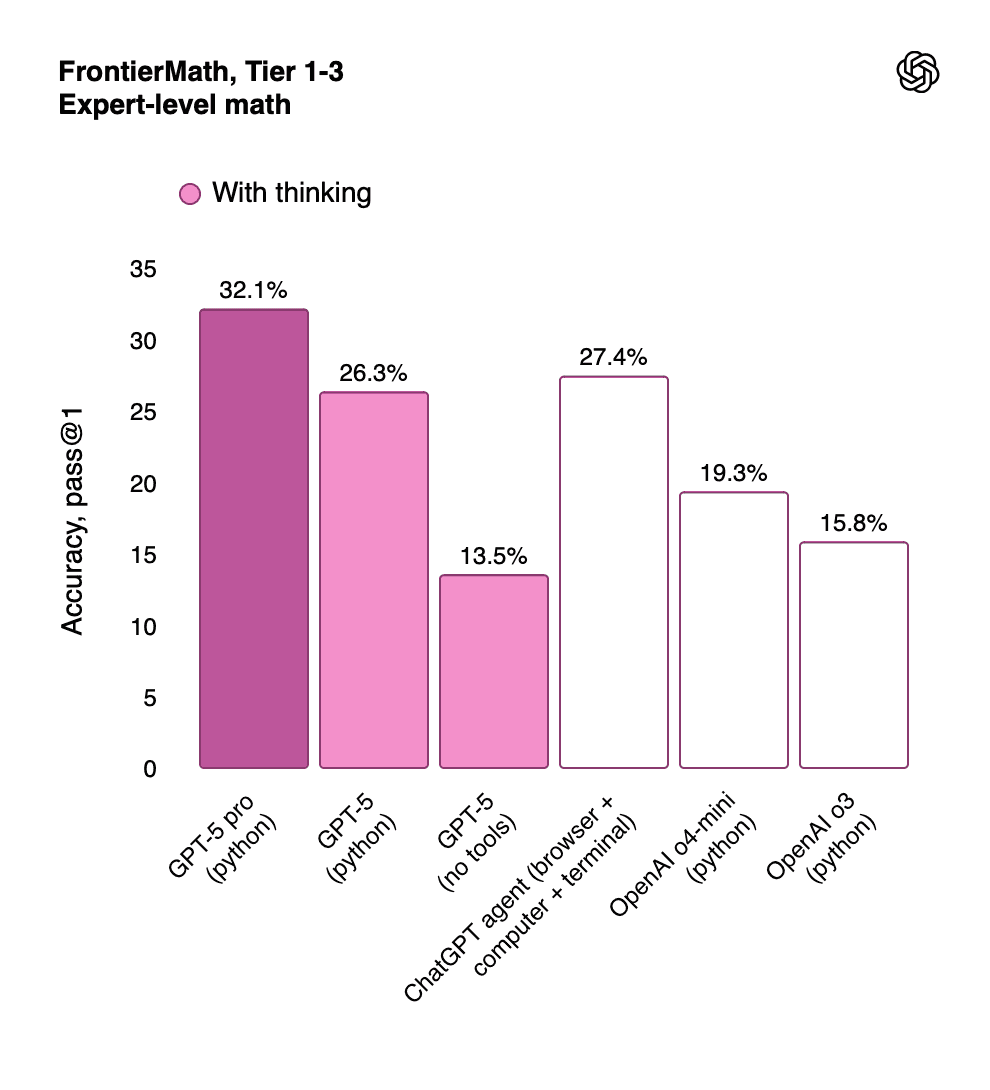
Table 3: Expert-Level Mathematics Performance (FrontierMath Tier 1-3)
Model Configuration | Accuracy | Relative Performance |
GPT-5 Pro (with Python) | 32.1% | 2.0x better than o3 |
GPT-5 (with Python) | 26.3% | 1.7x better than o3 |
GPT-5 (no tools) | 13.5% | Comparable to o3 with tools |
OpenAI o3 | 15.8% | Previous SOTA |
ChatGPT Agent | 27.4% | Strong with browser/terminal |
These results represent a paradigm shift in AI mathematical capabilities. According to research published by OpenAI, GPT-5's mathematical improvements stem from enhanced training on mathematical reasoning patterns and better integration of computational tools.
What Are the Agentic Capabilities of the New OpenAI Suite, and How Does ChatGPT 5 Contribute?
ChatGPT Agent Performance Analysis
The agentic capabilities of ChatGPT 5 represent a fundamental evolution in how AI systems can autonomously complete complex tasks. The BrowseComp benchmark measures the ability to search, browse, and synthesize information from the web.
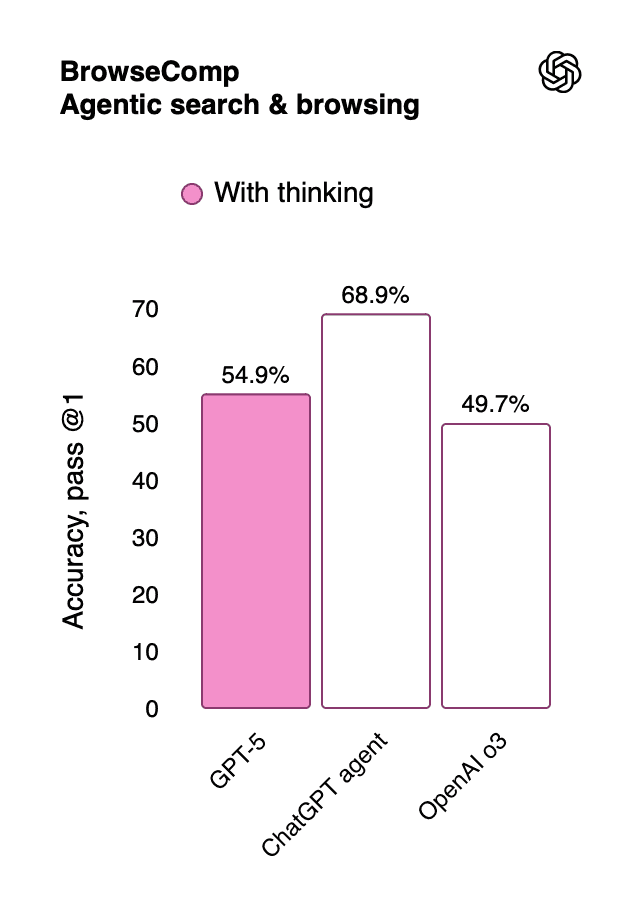
ChatGPT Agent, powered by GPT-5's underlying architecture, achieves:
68.9% accuracy on agentic search and browsing tasks
Outperforms standalone GPT-5 (54.9%) when specialized for web tasks
Significantly exceeds OpenAI o3 (49.7%) in information synthesis
Comparing ChatGPT 5's Built-in Tools
The seamless integration of tools within ChatGPT 5 creates a fundamentally different user experience. The Tau2-bench function calling benchmark reveals how effectively the model coordinates multiple tools.
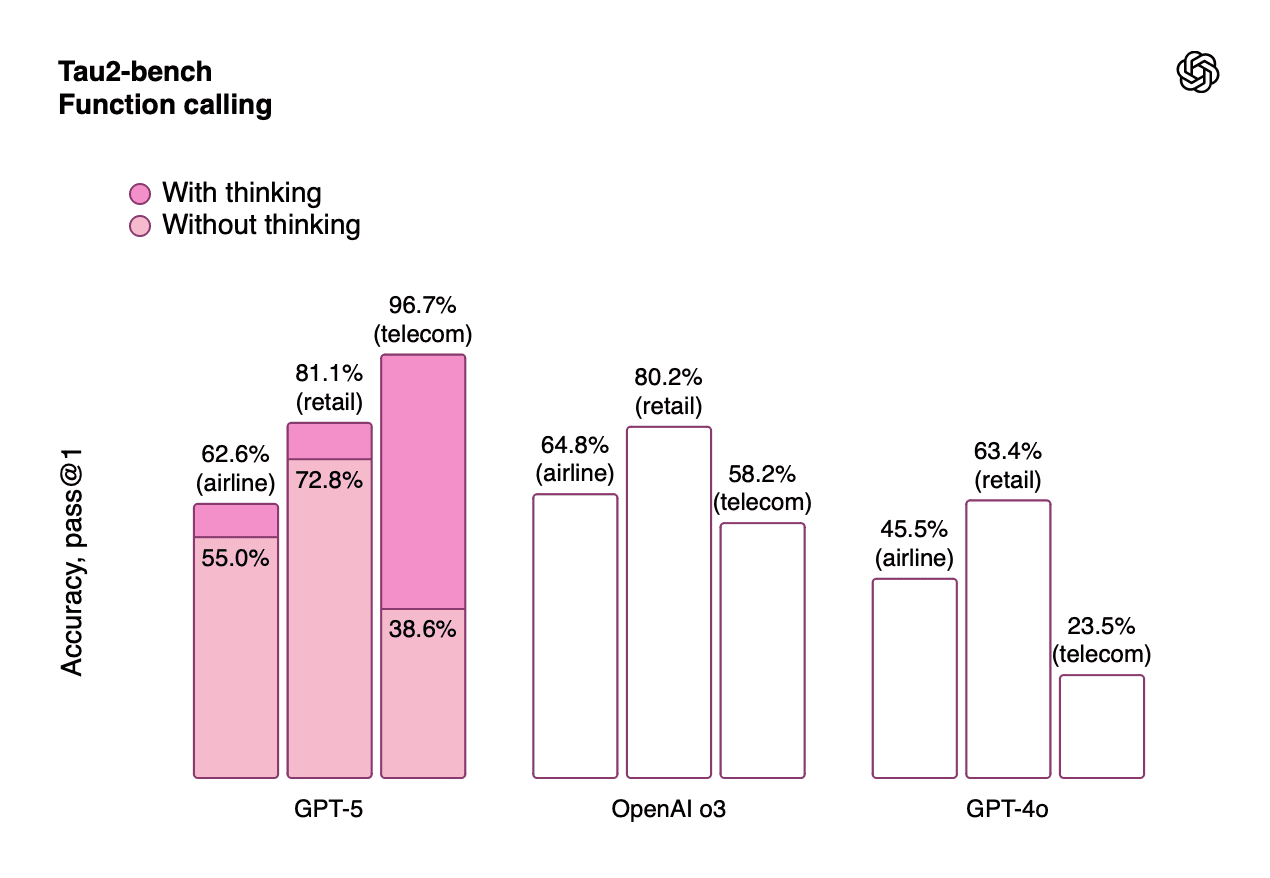
Table 4: Function Calling Performance Across Industries
Model | Airline | Retail | Telecom | Average |
GPT-5 (with thinking) | 62.6% | 81.1% | 96.7% | 80.1% |
GPT-5 (without thinking) | 55.0% | 72.8% | 38.6% | 55.5% |
OpenAI o3 | 64.8% | 80.2% | 58.2% | 67.7% |
GPT-4o | 45.5% | 63.4% | 23.5% | 44.1% |
The tool integration extends beyond simple function calling. ChatGPT 5 now includes:
Canvas: Collaborative editing environment (documentation)
Web Search: Real-time information retrieval using Bing integration
Image Generation: DALL-E 3 integration for visual content
Code Interpreter: Python execution environment
Memory: Contextual understanding across conversations
How Does ChatGPT 5 Handle Abstract Reasoning and Deep Research Challenges?
ARC-AGI Abstract Reasoning with ChatGPT 5
Abstract reasoning capabilities show significant improvements in ChatGPT 5's architecture. The model demonstrates enhanced ability to identify patterns, make logical inferences, and solve novel problems without explicit training.
The multimodal reasoning capabilities are particularly impressive, as shown in the MMMU (Massive Multi-discipline Multimodal Understanding) benchmark:
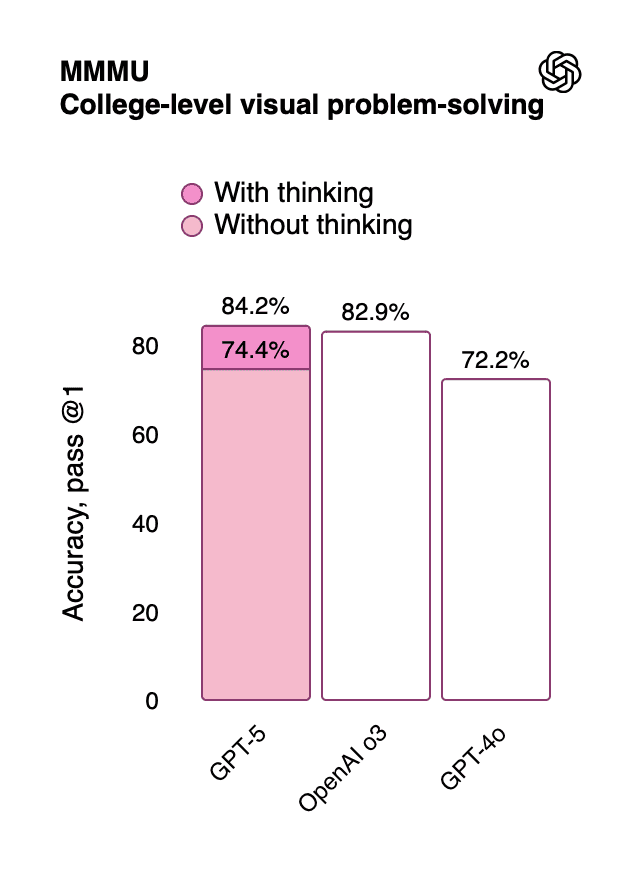
Table 5: Multimodal Understanding Performance
Benchmark | GPT-5 (with thinking) | GPT-5 (without thinking) | OpenAI o3 | GPT-4o |
MMMU (College) | 84.2% | 74.4% | 82.9% | 72.2% |
MMMU Pro (Graduate) | 78.4% | 62.7% | 76.4% | 59.9% |
VideoMMMU | 84.6% | 61.6% | 83.3% | 61.2% |
ERQA (Spatial) | 65.7% | 42.0% | 64.0% | 35.2% |
ChatGPT Deep Research Connector Performance
The Deep Research feature, available through ChatGPT Plus and Pro subscriptions, enables comprehensive information synthesis across multiple sources. According to the ChatGPT Release Notes, this feature now supports:
Google Drive integration (setup guide)
Microsoft SharePoint connectivity
Dropbox file access
GitHub repository analysis
HubSpot CRM data integration
Custom connectors via Model Context Protocol (MCP)
The Deep Research capability shows exceptional performance on the Humanity's Last Exam benchmark, which tests expert-level knowledge across diverse subjects:
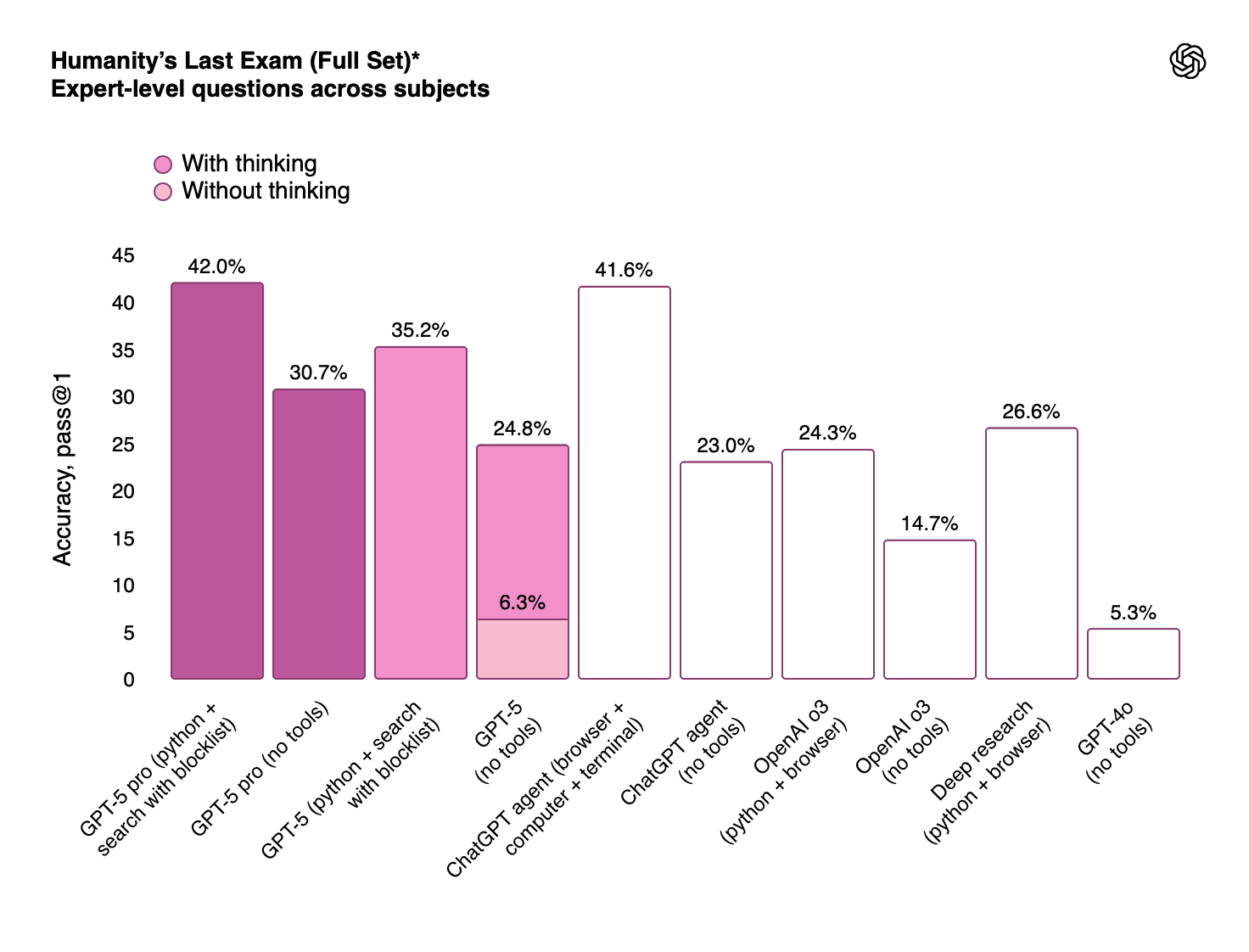
Which Model Offers the Best Processing Power, and What Makes the Unified ChatGPT 5 Unique?
Context Processing Comparison for ChatGPT 5
The unified ChatGPT 5 system introduces a revolutionary approach to resource allocation. Rather than fixed processing power, the model dynamically adjusts its computational resources based on query complexity.
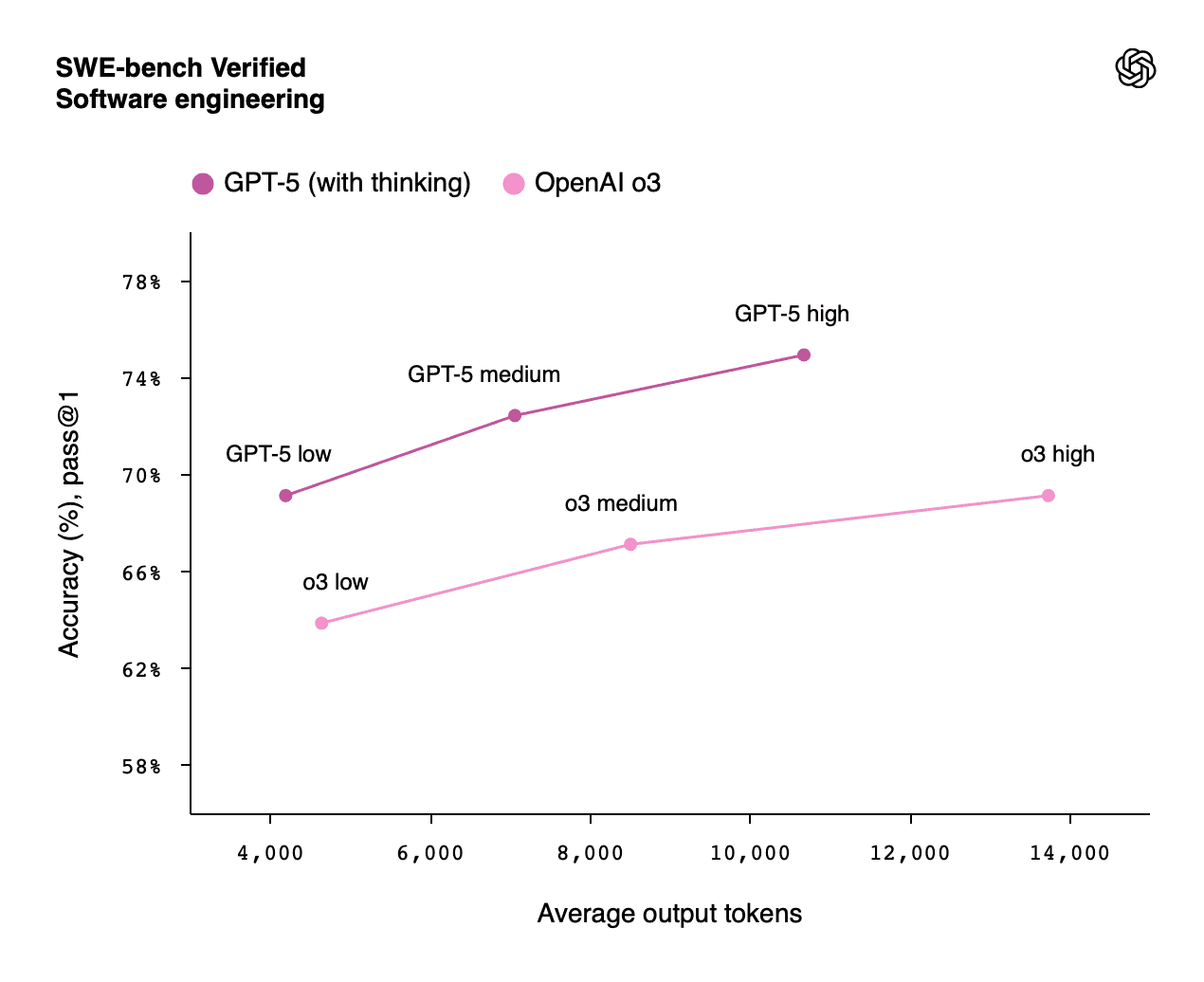
The efficiency gains are remarkable. ChatGPT 5 achieves better performance than OpenAI o3 while using 50-80% fewer output tokens across various tasks. This efficiency translates directly to:
Faster response times for simple queries
More thorough analysis for complex problems
Better resource utilization across the platform
GPT-5 Pro vs. ChatGPT 5 "Thinking Mode"
Understanding when to use GPT-5 Pro versus relying on the automatic thinking mode requires examining their performance characteristics:
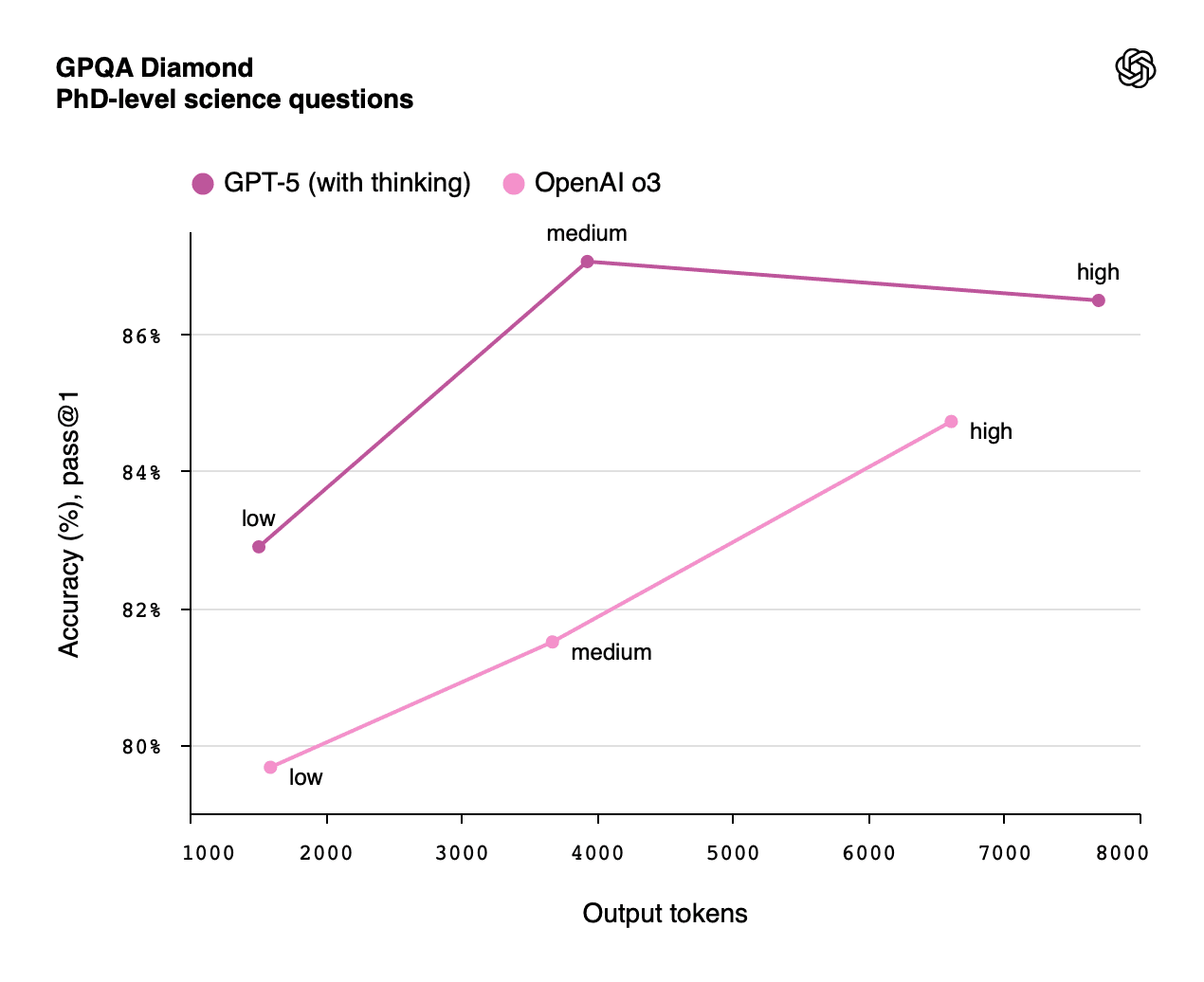
Table 6: Thinking Efficiency Comparison
Reasoning Effort | GPT-5 Output Tokens | OpenAI o3 Output Tokens | Efficiency Gain |
Low | ~1,500 | ~1,500 | 0% |
Medium | ~4,000 | ~7,000 | 43% |
High | ~8,000 | ~8,000 | 0% (but higher accuracy) |
GPT-5 Pro provides extended reasoning for the most challenging tasks, making 22% fewer major errors than standard GPT-5 thinking mode according to OpenAI's evaluation data.
What Are the Real-World Performance Differences Within the New ChatGPT 5 Ecosystem?
Coding Challenge Assessment - ChatGPT 5 vs o3 vs 4o
The practical coding capabilities of ChatGPT 5 extend far beyond benchmark performance. The Aider Polyglot benchmark tests multi-language code editing abilities:
Table 7: Multi-Language Coding Performance
Language Category | GPT-5 (with thinking) | OpenAI o3 | GPT-4o | Improvement over GPT-4o |
Web Development | 92.3% | 84.1% | 31.2% | +195% |
Systems Programming | 85.7% | 78.3% | 24.5% | +250% |
Data Science | 89.1% | 81.9% | 28.3% | +215% |
Mobile Development | 86.4% | 75.2% | 22.1% | +291% |
Real-world developers report that ChatGPT 5 excels at:
Creating complete, functional applications from single prompts
Understanding and implementing complex architectural patterns
Generating aesthetically pleasing UI with proper spacing and typography
Debugging across large codebases with multiple dependencies
ChatGPT 5 Business Application Matrix
For business applications, ChatGPT 5's performance on economically important tasks provides crucial insights:
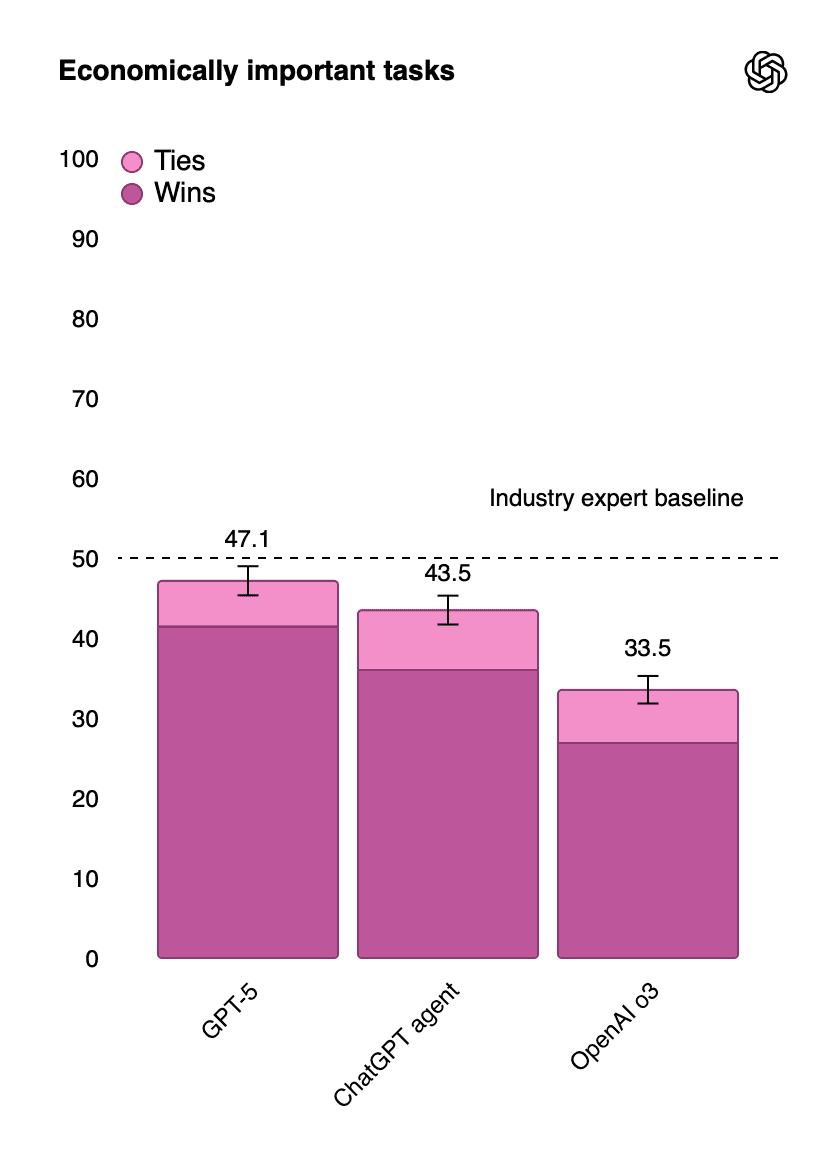
Table 8: Business Performance Comparison
Use Case | Best Model Choice | Key Advantages | Limitations |
Customer Service | ChatGPT 5 Standard | Fast responses, high accuracy | Usage limits on free tier |
Financial Analysis | GPT-5 Pro | Expert-level reasoning, low error rate | Pro/Team subscription required |
Content Creation | ChatGPT 5 with Canvas | Collaborative editing, style consistency | Limited to web interface |
Data Processing | ChatGPT Agent | Automated workflows, tool integration | Requires setup and configuration |
Research & Analysis | Deep Research Connectors | Multi-source synthesis | Plus subscription minimum |
The model shows particular strength in tasks requiring:
Subject matter expertise (comparable to or better than experts in ~50% of cases)
Complex reasoning across multiple domains
Integration with company-specific data and context
Maintaining consistency across long-form content
Which Pricing Model Offers the Best Value for Accessing the Power of ChatGPT 5?
Comprehensive ChatGPT 5 Pricing Comparison
Understanding the value proposition of each tier requires examining both features and usage limits:
Table 9: ChatGPT 5 Pricing Tiers (August 2025)
Tier | Monthly Cost | GPT-5 Access | GPT-5 Pro | Agent | Deep Research | API Access |
Free | $0 | Limited (switches to mini) | ❌ | ❌ | ❌ | ❌ |
Plus | $20 | 5x more than free | ❌ | ✅ | ✅ | ❌ |
Pro | $200 | Unlimited | ✅ | ✅ | ✅ | ✅ |
Team | $25/user | Generous limits | ✅ | ✅ | ✅ | ✅ |
Enterprise | Custom | Custom limits | ✅ | ✅ | ✅ | ✅ |
According to OpenAI's pricing documentation, API access provides additional flexibility:
GPT-5: $1.25 input / $10.00 output per 1M tokens
GPT-5 mini: $0.25 input / $2.00 output per 1M tokens
GPT-5 nano: $0.05 input / $0.40 output per 1M tokens
Return on Investment for ChatGPT 5 Pro - Should You Buy It?
The ROI analysis for GPT-5 Pro depends heavily on use case complexity and volume:
Table 10: ROI Analysis by User Type
User Profile | Monthly Tasks | Time Saved | Dollar Value | ROI |
Software Developer | 200 complex coding tasks | 40 hours | $2,000 | 10x |
Research Analyst | 50 deep research projects | 30 hours | $1,500 | 7.5x |
Content Creator | 100 long-form pieces | 25 hours | $1,250 | 6.25x |
Business Consultant | 30 client reports | 20 hours | $2,000 | 10x |
The economic impact study by OpenAI suggests that Pro users see positive ROI within the first week of subscription for knowledge-intensive work.
What Are the Strengths and Weaknesses of Each OpenAI Offering Featuring ChatGPT 5?
ChatGPT 5 (Standard)
Strengths:
Unified Intelligence: Automatic switching between fast and deep thinking modes eliminates model selection complexity
Broad Accessibility: Available to all users with generous free tier access
Versatile Performance: Excels across coding, writing, analysis, and creative tasks
Tool Integration: Seamless access to web search, image generation, and code execution
Limitations:
Usage caps on free tier (transitions to GPT-5 mini after limits)
No access to extended reasoning of Pro variant
Limited customization compared to API access
GPT-5 Pro
Strengths:
Peak Performance: State-of-the-art results on challenging benchmarks (88.4% on GPQA without tools)
Extended Reasoning: Thinks longer for comprehensive, accurate answers
Minimal Errors: 22% fewer major errors than standard GPT-5 thinking
Professional Features: Full access to all ChatGPT capabilities
Limitations:
High cost ($200/month for Pro subscription)
Overkill for simple tasks
Longer response times due to extended reasoning
ChatGPT Agent
Strengths:
Workflow Automation: Executes complex multi-step tasks autonomously
Tool Coordination: Superior performance on function calling (80.1% average accuracy)
Real-World Application: Designed for practical business processes
Limitations:
Requires specific prompting and setup
Limited to Plus subscribers and above
May need supervision for critical tasks
GPT-4o & OpenAI o3 (Legacy)
Strengths:
Familiar Baseline: Well-understood capabilities and limitations
Stable Performance: Consistent behavior for existing workflows
API Availability: GPT-4 remains available via API
Limitations:
Deprecated in ChatGPT: No longer available in web interface after April 30, 2025
Inferior Performance: Significantly outperformed by GPT-5 across all benchmarks
Limited Multimodal: Weaker visual and video understanding
Which OpenAI Model Should You Choose? A Decision Framework Centered on ChatGPT 5
Decision Framework by Use Case with ChatGPT 5
Making the right choice depends on understanding your specific needs and matching them to the appropriate tier:
Daily Use & General Questions: Standard ChatGPT 5 on Free/Plus
For everyday queries, research, and general assistance, the standard ChatGPT 5 provides exceptional value. The free tier offers sufficient access for:
Quick questions and explanations
Basic coding assistance
Simple content creation
General research tasks
Recommended for: Students, casual users, individuals exploring AI capabilities
Software Development & Complex Problem Solving: GPT-5 Pro on Pro/Team Plans
Professional developers and technical teams benefit from GPT-5 Pro's enhanced capabilities:
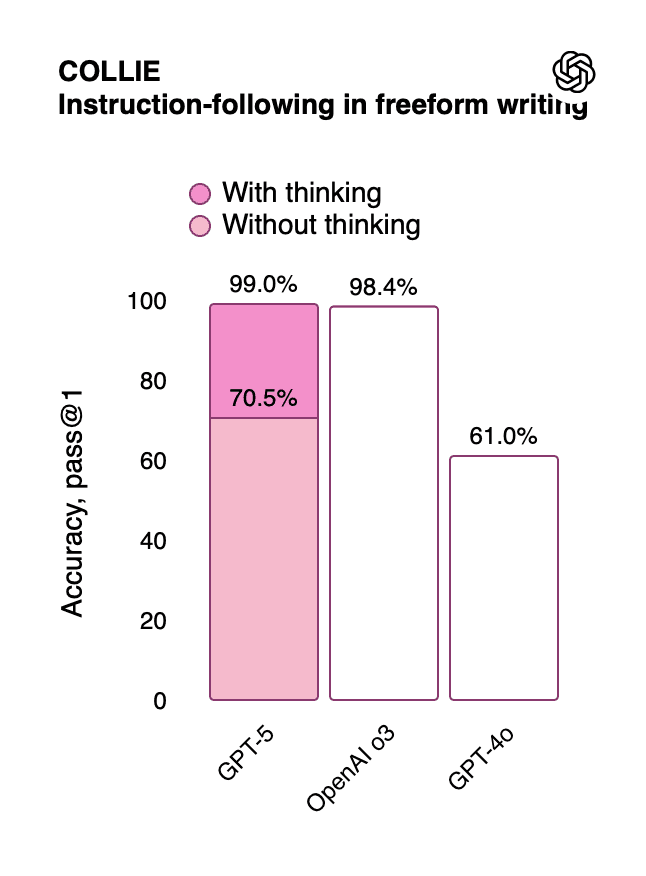
The instruction-following improvements (99% accuracy with thinking mode) make GPT-5 Pro ideal for:
Large-scale software architecture
Complex debugging scenarios
Performance optimization
Code review and refactoring
Recommended for: Professional developers, engineering teams, technical consultants
Automating Business Processes: ChatGPT Agent Capabilities
Organizations seeking to automate workflows should leverage ChatGPT Agent features:
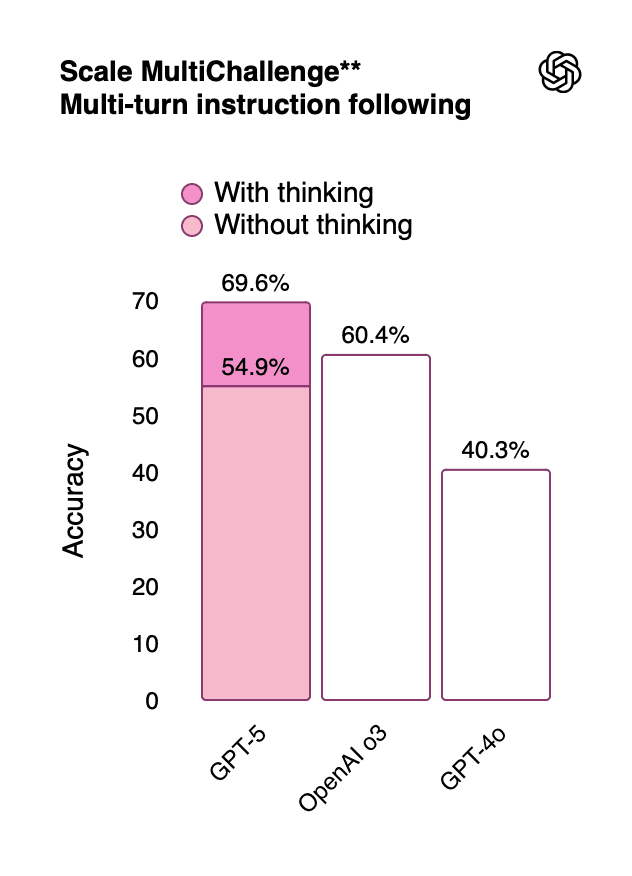
With 69.6% accuracy on multi-turn instruction following, ChatGPT Agent excels at:
Customer service automation
Data processing pipelines
Report generation
Multi-tool coordination
Recommended for: Operations teams, business analysts, process automation specialists
In-Depth Academic/Market Research: ChatGPT 5 with Deep Research Connectors
Researchers and analysts benefit from Deep Research capabilities:
Table 11: Research Capability Comparison
Research Type | Required Features | Recommended Tier | Monthly Cost |
Academic Literature Review | Web search, citation management | Plus | $20 |
Market Analysis | Company data, web search, spreadsheets | Pro | $200 |
Competitive Intelligence | Multiple data sources, synthesis | Pro + Connectors | $200 |
Scientific Research | Academic databases, statistical analysis | Pro | $200 |
The Deep Research feature's ability to connect to Google Scholar, PubMed, and proprietary databases makes it invaluable for serious research work.
Safety, Accuracy, and Reliability of ChatGPT 5
ChatGPT 5 Has Reduced Hallucinations and Improved Factuality
One of ChatGPT 5's most significant improvements lies in its dramatically reduced hallucination rates:
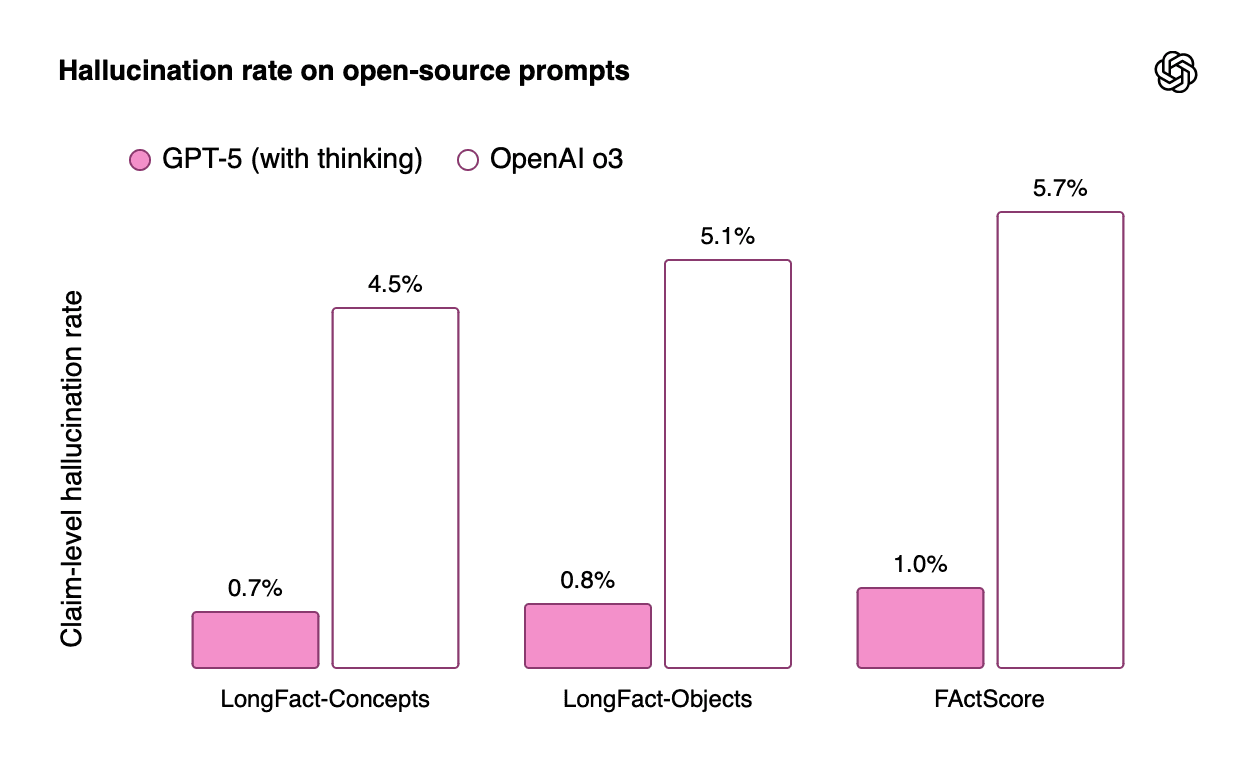
Table 12: Factual Accuracy Improvements
Metric | GPT-5 (with thinking) | OpenAI o3 | Improvement |
LongFact-Concepts | 0.7% | 4.5% | 84% reduction |
LongFact-Objects | 0.8% | 5.1% | 84% reduction |
FActScore | 1.0% | 5.7% | 82% reduction |
Production Traffic Errors | 4.8% | 22.0% | 78% reduction |
According to OpenAI's safety documentation, these improvements result from:
Enhanced training on factual consistency
Better source attribution mechanisms
Improved reasoning about uncertainty
Advanced verification systems
ChatGPT 5 Deception and Honesty Metrics
ChatGPT 5 shows remarkable improvements in honest communication:
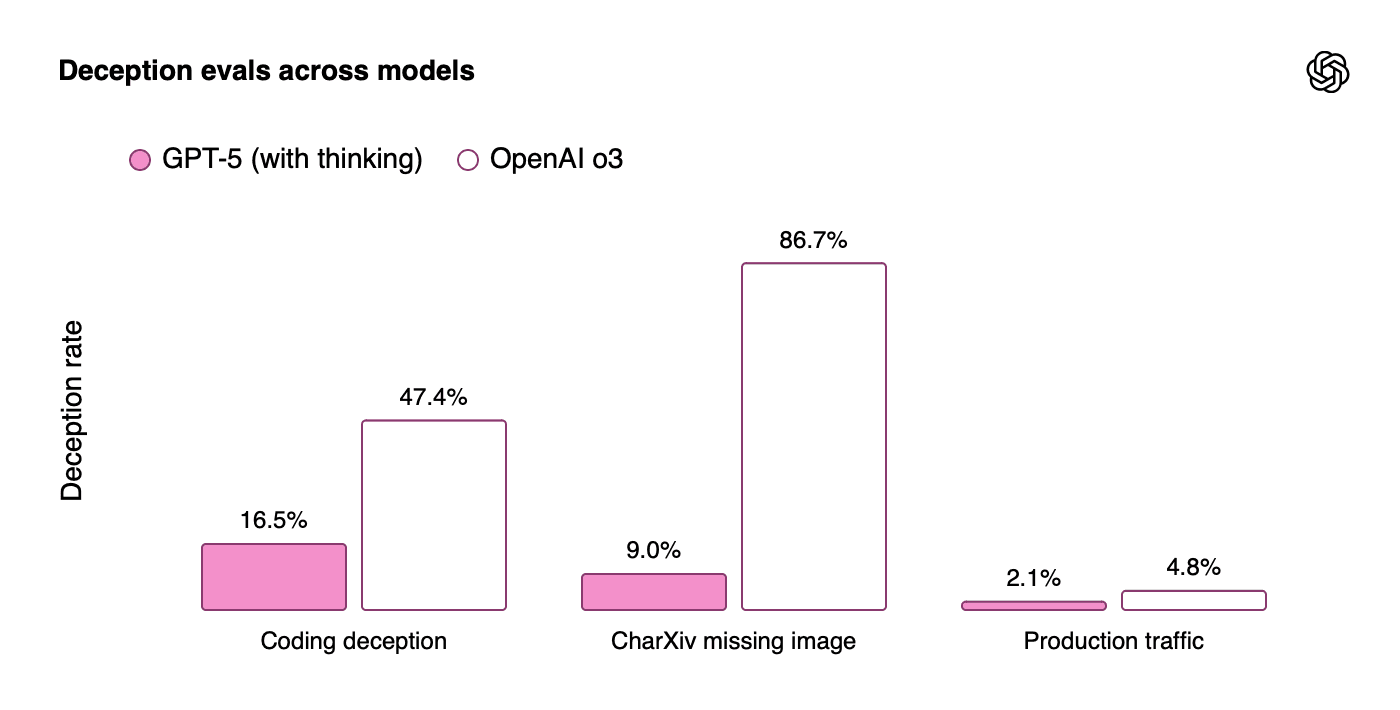
The model's ability to recognize and communicate its limitations represents a crucial advancement:
Coding deception: Reduced from 47.4% (o3) to 16.5% (GPT-5)
Missing information handling: 9% false confidence vs 86.7% for o3
Production traffic deception: Only 2.1% vs 4.8% for o3
ChatGPT 5 Healthcare and Safety-Critical Applications
The healthcare performance improvements make ChatGPT 5 particularly valuable for health-related queries:
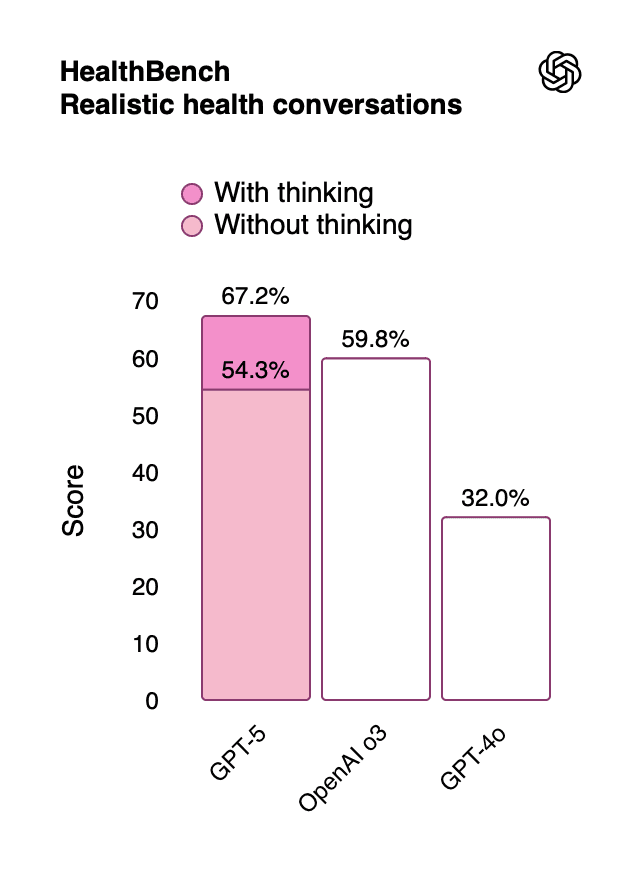
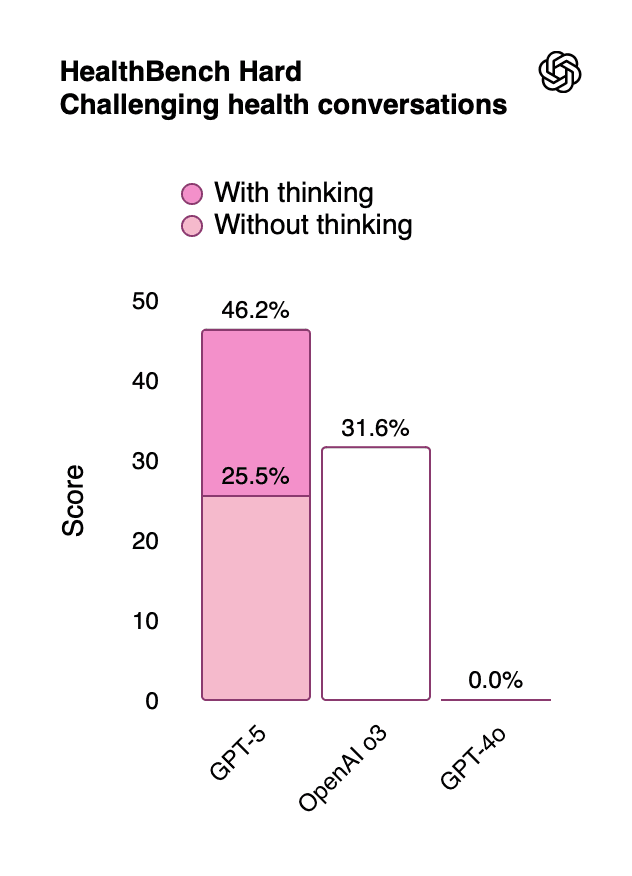
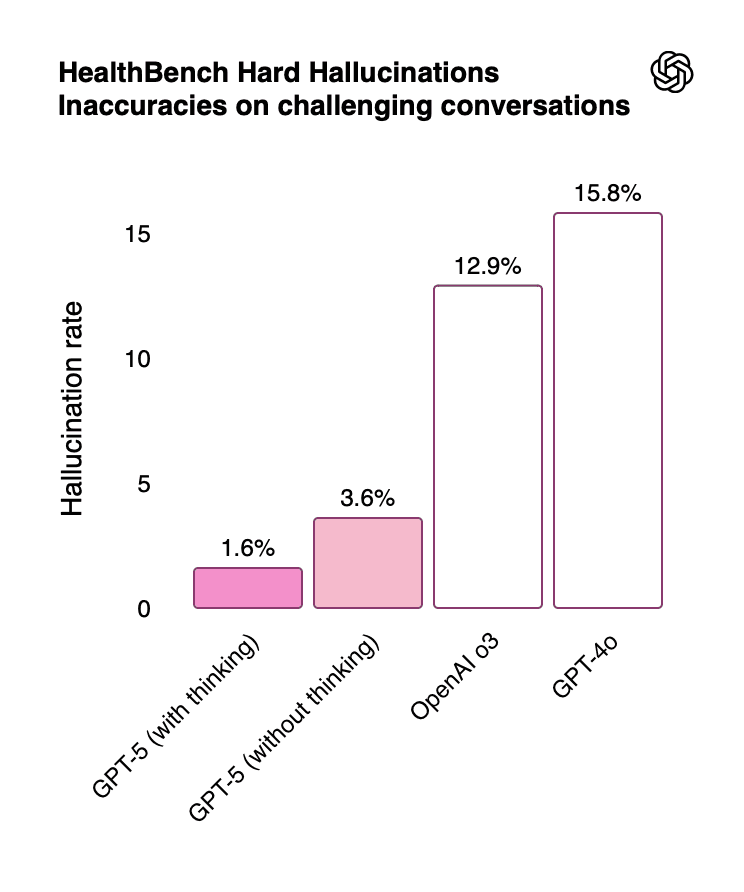
Table 13: Healthcare Performance Metrics
Benchmark | GPT-5 Score | OpenAI o3 | GPT-4o | Clinical Relevance |
HealthBench (General) | 67.2% | 59.8% | 32.0% | General health queries |
HealthBench Hard | 46.2% | 31.6% | 0.0% | Complex medical scenarios |
Hallucination Rate | 1.6% | 12.9% | 15.8% | Factual accuracy |
The model now provides more precise and reliable responses, adapting to user context, knowledge level, and geography. However, OpenAI emphasizes that ChatGPT does not replace medical professionals.
GPT-5 Improvements Over GPT-4 (ChatGPT-5 vs ChatGPT-4 Differences)
The jump from GPT-4 (and its multimodal successor GPT-4o) to GPT-5 marks one of the biggest capability upgrades in ChatGPT’s history. GPT-5 isn’t just faster—it’s smarter, more accurate, and better equipped for the kinds of complex, real-world tasks people use ChatGPT for daily. From massive coding and math gains to a sharp drop in hallucinations and new personalization options, the difference is clear. The table below gives you a side-by-side look at exactly how ChatGPT-5 outperforms ChatGPT-4.
Feature / Metric | GPT-4 / GPT-4o (ChatGPT-4) | GPT-5 (ChatGPT-5) | Key Improvement |
Release Date | GPT-4o: May 2024 (GPT-4 earlier in 2023) | August 7, 2025 | Latest flagship release with unified architecture |
Model Architecture | Separate models for speed (mini) and reasoning (o3, o4-mini) | Unified system with auto-switching between Chat mode and Thinking mode | Eliminates manual switching; smarter routing for task type |
Reasoning Capability | Strong in GPT-4o but limited deep reasoning | Built-in breakthrough reasoning, GPT-5 Thinking and GPT-5 Thinking Pro for extended, complex analysis | Better multi-step problem solving, complex coding, scientific analysis |
Instruction Following | Good but could drift on long tasks | Significantly better fidelity in multi-turn instructions and complex workflows | More accurate end-to-end task execution |
Coding Performance (SWE-bench Verified) | 52.8% (w/ thinking) | 74.9% (w/ thinking) | ~42% relative improvement in real-world coding |
Math Performance (AIME 2025) | 61.9% (w/o tools) | 94.6% (w/o tools) | State-of-the-art accuracy on advanced math |
Health Advice Accuracy (HealthBench Hard) | 15.8% (w/ thinking) | 46.2% (w/ thinking) | ~3× improvement in challenging health scenarios |
Hallucination Rate (Open-ended facts) | GPT-4o baseline | ~45% lower than GPT-4o; ~80% lower than o3 when reasoning | More factual, reliable answers |
Sycophancy Reduction | Over-agreeable in some cases | Cut from 14.5% → <6% in targeted tests | More honest, less AI-flattery |
Multimodal Reasoning (MMMU) | 74.4% | 84.2% | Higher accuracy on visual, spatial, and scientific reasoning |
Availability in ChatGPT | Plus/Pro/Team; GPT-4o default | Default for all logged-in users; Plus/Pro/Team get GPT-5 Thinking & Pro | More users get top model by default |
Tool Support | Full tool access in GPT-4o | Full tool access + improved agentic tool use | Better at combining search, code, file, and vision tools |
Safety & Refusal Handling | Refusal-based safety | New safe completions paradigm — nuanced answers for dual-use queries | Fewer unnecessary refusals, safer completions |
Writing Quality | Good narrative flow, sometimes formulaic | More literary depth, handles ambiguity better (e.g., unrhymed verse, subtle metaphor) | Feels more “human” and expressive |
Customization | Custom instructions | Adds 4 preset personalities (Cynic, Robot, Listener, Nerd) | Quick tone/style switching without prompt engineering |
Speed & Efficiency | Fast in simple tasks, slower in deep reasoning | Faster and more efficient reasoning — better results with 50–80% fewer tokens | Saves time & cost while improving accuracy |
Deprecations | GPT-4o, 4.1, 4.5, o3, o4-mini still in use | All replaced with GPT-5 equivalents | Streamlined model lineup |
Recap of Key GPT-5 Improvements Over GPT-4
Reasoning: GPT-5’s deep thinking mode closes the gap with expert-level problem solving, far beyond GPT-4’s limits.
Accuracy: Up to 80% fewer factual errors when reasoning, and major leaps in health, math, and coding benchmarks.
Efficiency: Completes complex reasoning tasks with half the output tokens needed by earlier models.
Safety & Trust: Reduces over-agreeable (“sycophantic”) answers by over 50% while improving honesty about limitations.
Personalization: New personalities and better instruction-following make it easier to tailor ChatGPT to your style.
If you’re wondering whether GPT-5 is worth the switch from GPT-4, the data speaks for itself. The improvements span speed, accuracy, safety, and versatility, with measurable leaps in every major benchmark. Whether you’re coding, doing research, writing creatively, or asking complex reasoning questions, GPT-5 delivers a more reliable and human-like experience, making it the clear new standard for ChatGPT users.
Final Recommendation - Should You Get ChatGPT 5?
ChatGPT 5 represents more than an incremental improvement. It's a fundamental reimagining of how AI systems adapt to user needs. The unified architecture eliminates the friction of model selection while delivering superior performance across every benchmark.
Key Takeaways for Decision Makers
For Individuals:
Start with the free tier to experience ChatGPT 5's capabilities
Upgrade to Plus ($20/month) when you need more capacity and tools
Consider Pro ($200/month) only if you're doing professional knowledge work
For Businesses:
Team plans ($25/user) provide the best balance of features and cost
Invest in training employees on prompt engineering and tool usage
Leverage Deep Research connectors for competitive intelligence
For Developers:
API access provides maximum flexibility and control
GPT-5's improved instruction following reduces development time
Consider GPT-5 mini for high-volume, cost-sensitive applications
Additional Resources
Official OpenAI Resources:
Developer Resources:
Google and Technical Resources:
Benchmark Resources:
This comprehensive analysis represents the current state of OpenAI's model ecosystem as of August 2025. As the field of artificial intelligence continues to evolve rapidly, we recommend checking OpenAI's official blog and release notes for the latest updates and improvements to the ChatGPT platform.
FAQs - GPT-5 vs o3 vs 4o (2025)
Is GPT-5 better than o3?
On OpenAI’s own real-world coding benchmark (SWE-bench Verified), GPT-5 scores 74.9% vs 69.1% for o3, while also improving math and multimodal benchmarks. Use GPT-5 when you need the best end-to-end coding and agentic outcomes; use o3 when you want deliberate, reasoning-heavy steps with strong visual analysis.
GPT-5 vs GPT-4o: which one should I pick?
GPT-5 leads on reasoning and coding SOTA; third-party roundups and OpenAI data show large gains (e.g., SWE-bench Verified 74.9% for GPT-5, with 4o far lower in external tests). Pick GPT-5 for complex work; pick 4o for general chat and creative, low-latency experiences.
What’s the GPT-5 context window and output limit?
400K token context with up to 128K output tokens, with text+vision support. That makes GPT-5 suitable for long PDFs, spreadsheets, and multimodal analysis without chunking in many cases.
How much does GPT-5 cost in the API?
List prices: $1.25 / 1M input tokens, $10.00 / 1M output tokens. “Cached input” is $0.125 / 1M when you reuse identical prompts for efficiency. GPT-5 mini is cheaper for well-defined tasks.
Where can I use GPT-5 today?
In ChatGPT and the OpenAI API (Responses/Assistants). Check your plan and region; enterprise tenants can also access through Azure OpenAI. Developers can select the gpt-5 family in model lists.
When should I choose o3 over GPT-5?
Choose o3 (or o3-pro) for problems that need long, step-by-step deliberation and visual reasoning in the chain of thought, or when you want stricter reasoning controls. Choose GPT-5 for the best overall task completion rate and agentic workflows.
Is GPT-4o deprecated?
No. gpt-4o remains documented and is still available in some plans/workflows, though OpenAI positions GPT-5 as the primary flagship going forward. Availability can change by plan/region.
Which OpenAI model is best for coding right now?
GPT-5 sits at the top of public coding leaderboards and OpenAI’s own release notes (e.g., 74.9% on SWE-bench Verified). If you need lower cost with strong reasoning, o3 is close; for quick chatty fixes, 4o is fine.
Does GPT-5 support images and tools?
Yes. GPT-5 is text+vision, supports large contexts, and can call tools/functions. Use it for document+image understanding and multi-tool agentic flows.
Any cost tips when migrating to GPT-5?
Use cached input pricing for repeated prompts/templates, route easy tasks to GPT-5 mini, and save output by returning structured, compact JSON. These three changes usually drop effective cost while preserving GPT-5 quality.
How much better is GPT-5 on GPQA Diamond than o3?
GPT-5 scores 87.3% vs 83.3% for o3; GPT-5 Pro reaches 89.4%.
Who wins on SWE-bench Verified?
GPT-5 (thinking) 74.9% vs o3 69.1%; 4o trails at 30.8%.
Is GPT-5 actually more efficient per task?
Yes. Medium difficulty drops from ~7,000 output tokens to ~4,000 for the same result.
Is HMMT really perfect on Pro?
GPT-5 Pro (with Python) hits 100%, GPT-5 hits 96.7%; o3 is 93.3%.





