SEO

Join 500+ brands growing with Passionfruit!
When someone asks ChatGPT, "What's the best CRM for a 50-person SaaS company?", the model breaks that prompt into multiple sub-queries, sends them to a search engine, retrieves chunks of text, evaluates those chunks for relevance, and assembles a response with citations attached.
That process determines which brands get recommended and which get ignored. Understanding these mechanics is now the foundation of every GEO and AEO strategy worth running.
Our piece synthesizes twelve months of research on how LLMs search the web, what predicts citation, and where retrieval breaks down.

How Does ChatGPT Decide When to Search the Web?
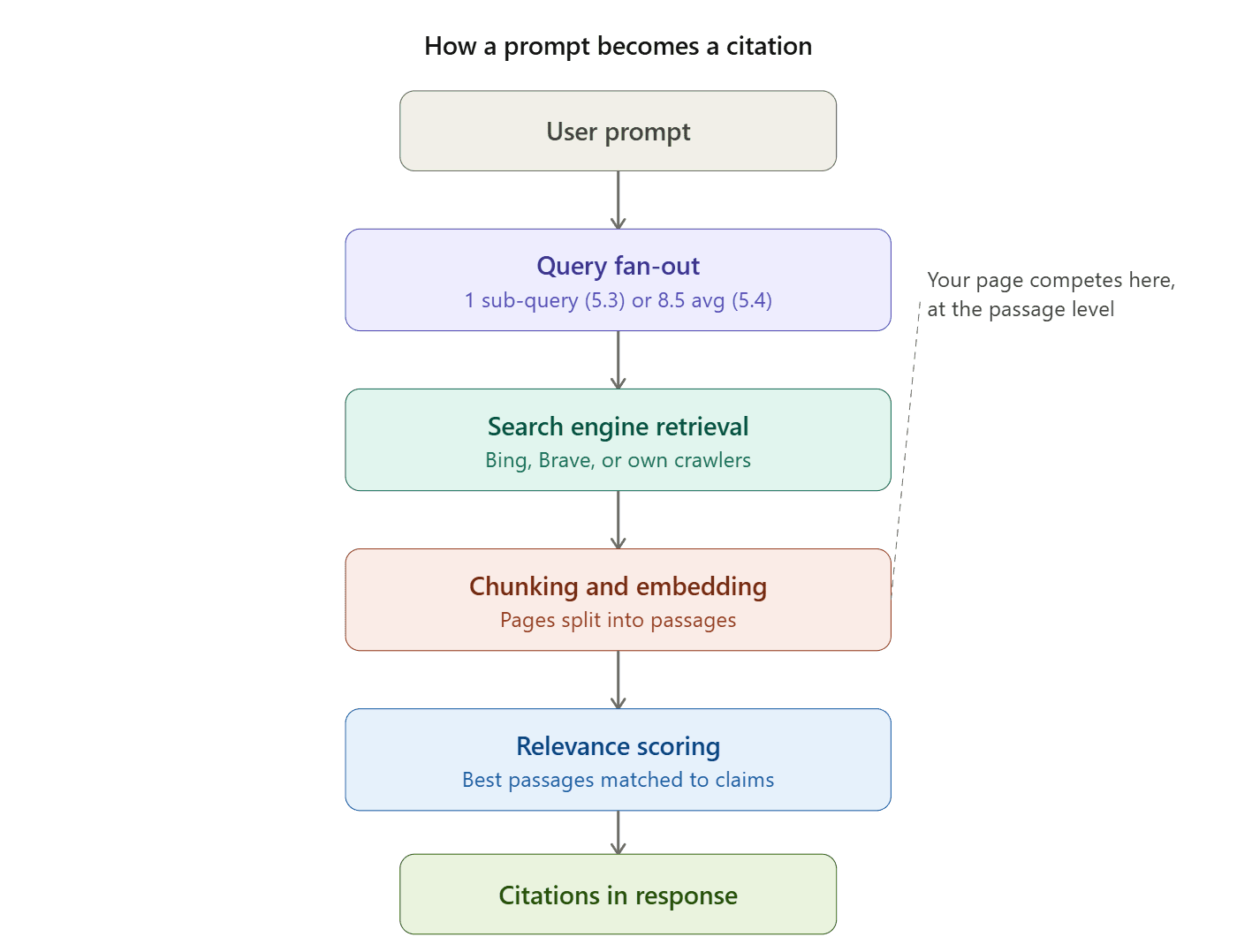
Before citing anything, the model makes a binary decision: answer from memory or search the web. Most users assume ChatGPT always searches. It does not.
ChatGPT's system prompt triggers a web search for up-to-date or location-specific information. Both OpenAI and Anthropic have confirmed they use search engines like Bing and Brave, plus their own crawlers.
Writesonic's March 2026 study of 50 prompts across ChatGPT's newest models found that GPT-5.4 Thinking skipped search on 4 of 50 prompts. But GPT-5.4 still cited 17 sources from training data alone on a robot vacuum prompt. GPT-5.3 produced zero citations when it did not search.
Prompts with a year ("in 2026"), price constraints ("under $500"), or comparison structure ("X vs Y") triggered search 100% of the time on both models. If your content targets these query patterns, you are more likely to enter the retrieval pipeline.
ChatGPT's user bot does not render JavaScript, so pages need pre-rendered HTML. This is a basic technical SEO requirement that now directly affects AI visibility.
What Is Query Fan-Out and How Does It Affect AI Citations?
When a model searches, it does not run a single query. It decomposes the prompt into multiple sub-queries, a process called query fan-out.
Google coined the term at Google I/O 2025, when Head of Search Elizabeth Reid explained that the system breaks questions into subtopics and issues multiple queries simultaneously. ChatGPT uses a similar mechanism.
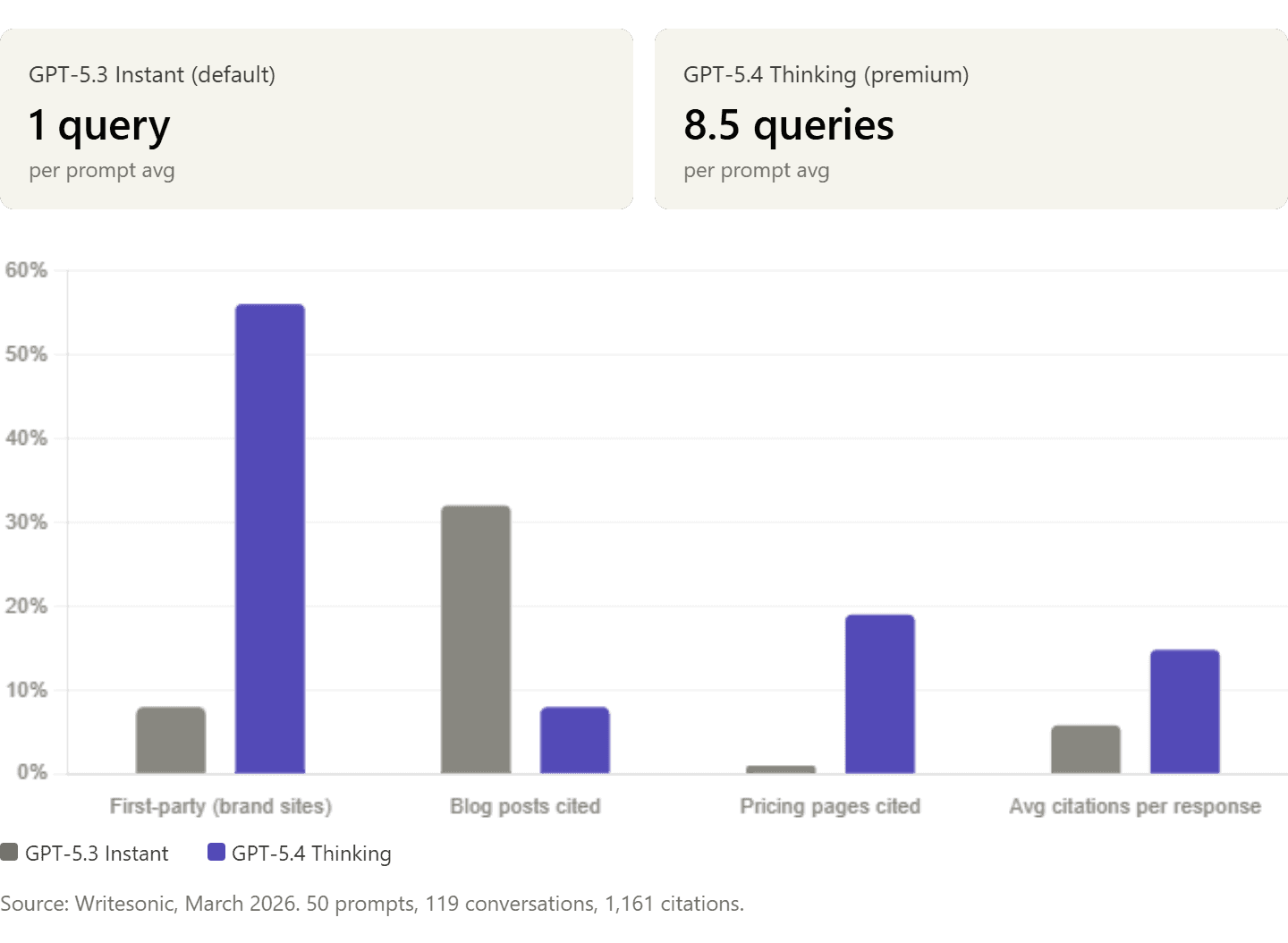
The scale varies dramatically by model:
GPT-5.3 Instant (default): 1 query per prompt.
GPT-5.4 Thinking (premium): 8.5 queries per prompt.
GPT-5.4 follows a two-phase pattern: first, domain-restricted queries to brand sites ("site:klaviyo.com pricing email marketing 2026"), then validation against review platforms ("G2 ecommerce email marketing software 2026" restricted to g2.com). This explains why GPT-5.4 cites brand websites 56% of the time while GPT-5.3 cites them only 8%.
Your page does not need to rank for the user's exact prompt. It needs to match the sub-queries the model generates. A page ranking #4 for "best project management software" might get skipped if a competitor ranks for "Asana vs Trello for remote marketing teams," which is the sub-query ChatGPT actually ran. Prompt engineering for SEO and understanding fan-out behavior are becoming core skills.
How Do LLMs Retrieve and Select Content to Cite?

The model does not read entire web pages. It sees chunks or passages. For each sub-query, the system processes retrieved content through chunking (splitting into semantically coherent passages), embedding (transforming passages into vectors), and dense retrieval (similarity search for the most relevant passages).
Your page competes at the passage level, not the document level. If your pricing section is buried under 2,000 words of marketing copy, the relevant chunk may never surface. This is the critical point for AI search visibility.
Citations are attached to passages that survived every pipeline stage: query decomposition, search ranking, chunk extraction, embedding similarity, and relevance scoring. A page can rank on Google for a keyword and still not appear in ChatGPT's citations if the model decomposed the prompt into sub-queries your page does not address.
Structured data and schema markup speed up classification by providing machine-readable context, making it easier for AI to lift your content into answers.
What Content Characteristics Predict LLM Citations?
Multiple independent studies show consistent patterns.
Front-loaded structure wins
Kevin Indig's analysis of 1.2 million ChatGPT answers found 44.2% of citations come from the first 30% of content (the "ski ramp" pattern). LLMs are trained on journalism that leads with the bottom line. Put critical information early, not after long introductions.
Entity density beats depth
Heavily cited text averaged 20.6% entity density, three to four times normal English. ChatGPT favors definite language, question marks in headings, and simple sentence structures. Winning content averaged a Flesch-Kincaid grade of 16 versus 19.1 for lower performers. If you are writing SEO content with AI tools, this is the stylistic target.
Freshness acts as a retrieval signal
Ahrefs' analysis of 17 million citations found strong bias toward recently updated content. GPT-5.3 retrieves only 6% of web results under 30 days old (down from 33% on GPT-5.2). Adding "last updated" dates and refreshing statistics regularly directly affects retrieval probability.
Domain authority correlates with citation frequency
Most ChatGPT citations come from domains with DR above 60. Sites with 32,000+ referring domains are 3.5x more likely to be cited than those with under 200. The correlation exists because high-authority sites rank better in the search engines LLMs use for retrieval. Earning quality backlinks remains foundational for AI visibility.
Domains with G2, Capterra, Trustpilot, and Yelp profiles have 3x higher citation probability. Third-party validation strengthens the entity signals models use when deciding which brands to investigate.
Which Page Types Do LLMs Cite Most Often?
Branded queries: reviews dominate
Omniscient Digital's analysis of 23,387 citations found 57% of branded query citations go to reviews, listicles, forums, and case studies. Directory sites captured 17%. Product pages: 12%. Thought leadership: only 5.4%.
Branded queries ask "validate this decision," not "teach me." For branded visibility, invest in comparison content and social proof over purely educational posts.
Non-branded queries: thinking models favor commercial pages
GPT-5.3 sends 32% of citations to blog posts. GPT-5.4 sends only 8% to blogs, directing 19% to pricing pages, 22% to homepages, and 10% to product pages. Combined, 51% of GPT-5.4's citations land on commercial pages.
Writesonic found 4 pricing page citations on GPT-5.3 versus 138 on GPT-5.4. If your pricing page hides numbers behind "contact sales," GPT-5.4 cites a competitor instead. For e-commerce, optimizing product pages for AI is now essential.
The "kingmaker" sites for default models
GPT-5.3 cites third-party sources almost exclusively. Top intermediaries: Forbes (15 citations), TechRadar (10), Tom's Guide (10), Reddit (7). If your brand does not appear on these sites, it likely does not appear in default model responses. Digital PR that secures coverage on kingmaker domains now has a direct AI visibility payoff.
Do Google Rankings Help You Get Cited by ChatGPT?
It depends on the model.
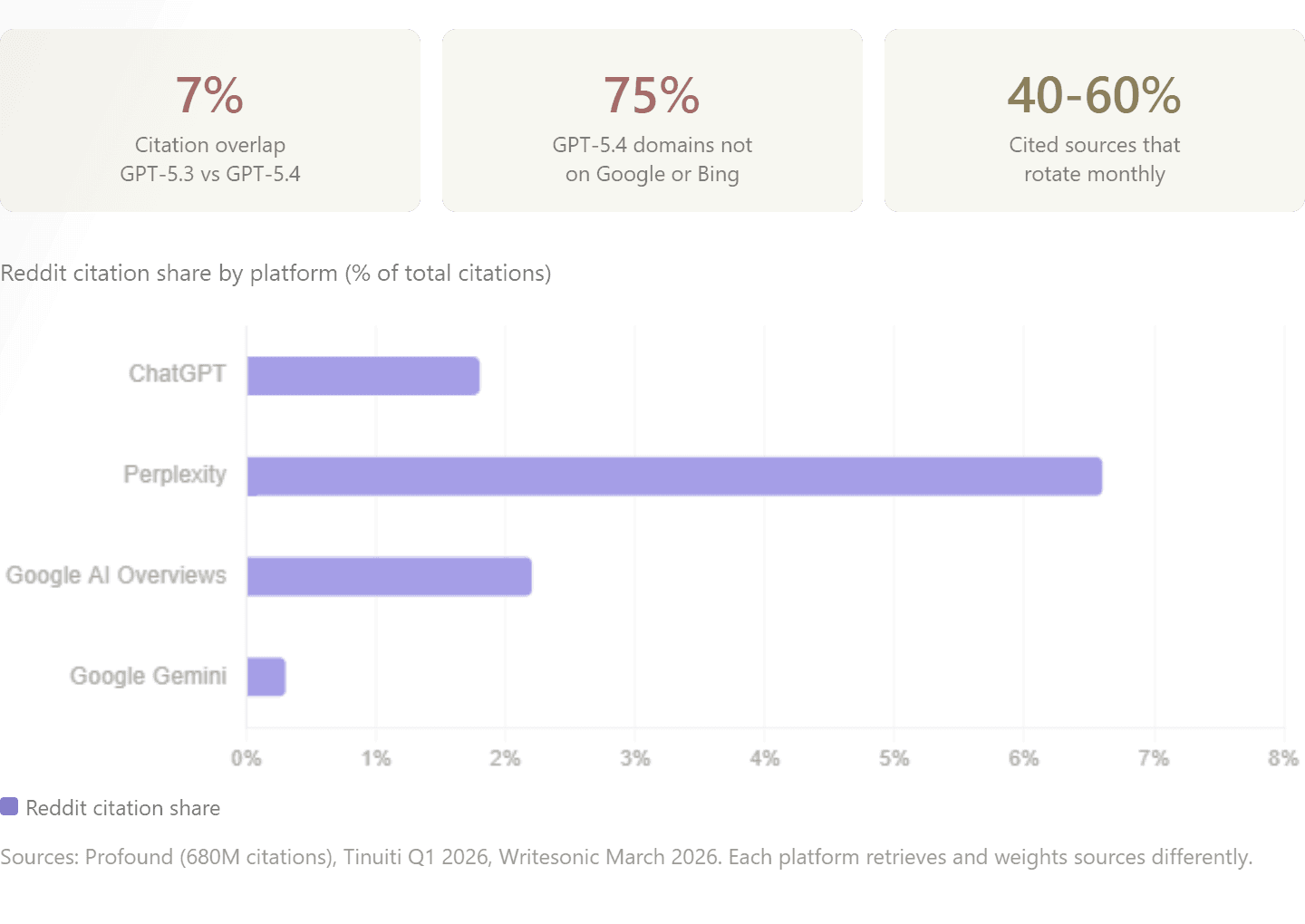
47% of GPT-5.3's cited domains also rank on Google. But 44% come from domains not on Google or Bing. For GPT-5.4, 75% of cited domains appear in neither search engine, because the model identifies brands from training data and queries their sites directly.
Google AI Overviews show the strongest link to traditional rankings: 76.1% of cited URLs also rank in Google's top 10. AI Overviews reward traditional SEO. Thinking models reward brand recognition and first-party content quality.
An SEO strategy that only optimizes for traditional rankings captures half of AI visibility and misses the rest.
Why Do LLMs Get Citations Wrong? The Hallucination Problem
Support rates are lower than assumed
The SourceCheckup study (Nature Communications, Wu et al. 2025) evaluated seven LLMs on 800 medical questions and 58,000 statement-source pairs. Between 50% and 90% of responses are not fully supported by cited sources. Even GPT-4o with RAG had ~30% of individual statements unsupported.
This aligns with patterns visible when comparing AI models: retrieval accuracy varies significantly.
Hallucinated citations are systemic
Across 13 models, hallucinated citation rates range from 14.23% to 94.93%. CiteVerifier analysis of 2.2 million citations from 56,381 papers found 1.07% contained fabricated citations, increasing 80.9% in 2025. At NeurIPS 2025, at least 53 accepted papers contained hallucinated citations.
Monitoring AI citations for correctness is now as important as monitoring frequency.
RAG fixes URLs but not accuracy
RAG-enabled models cite real pages but still fail to fully support their claims nearly half the time. Models extrapolate beyond retrieved information, blending search results with pretraining knowledge.
If your content contains ambiguous language, a model may cite it to support a claim you never made. Writing with precision (specific numbers, named entities, definite language) reduces misattribution risk.
Why Do Different AI Platforms Cite Different Sources?
Minimal overlap between models
Writesonic found only 7% citation overlap between GPT-5.3 and GPT-5.4. On 22 of 50 prompts, overlap was zero.
Tinuiti's Q1 2026 report across seven platforms concluded: there is no universal top source. Profound found Reddit at 1.8% of ChatGPT citations but 6.6% on Perplexity. Google AI Overviews cited Reddit at 44% of social citations; Google Gemini at 5%. Semrush captured ChatGPT's Reddit citation share dropping from 60% to 10% within weeks.
Each platform rewards different signals
ChatGPT provides clickable links. Perplexity emphasizes domain authority. Google prioritizes SERP-level brand visibility. Your measurement framework needs to track AI traffic per platform, not in aggregate. AI search referrals only make sense when measured per source.
How to Optimize Your Content for LLM Citations
Treat fan-out queries as keyword research. Map content against the sub-queries models generate, not just the user's original prompt. Tools like Keywords Everywhere extract actual fan-out queries. This extends traditional keyword research into the AI layer.
Restructure for chunk-level retrieval. Each H2 section should be a self-contained, citable unit. Front-load key information. Use question-based headings. FAQ schema reinforces these structures for both traditional and AI search.
Make commercial pages citable. Put real pricing in plain text. Structure comparisons in tables. Remove "contact sales" gates. For e-commerce, AI-optimized product pages are as important as Google-optimized ones.
Build the entity layer. G2, Capterra, Trustpilot, Wikipedia, and Reddit presence all signal brand legitimacy. Use structured data to make entity signals machine-readable.
Monitor per model. GPT-5.3 and GPT-5.4 have 7% overlap. Set up tracking per platform with AEO/GEO tools.
Prioritize precision. Models cite your content to support claims you may not have made. Use specific numbers, named entities, and clear statements. Citation optimization is about accuracy, not just volume.
The search market has split. One-half runs on rankings. The other runs on retrieval, chunking, and citation selection. Understanding the retrieval pipeline is the working knowledge that separates informed GEO strategy from guesswork.
Frequently Asked Questions
How does ChatGPT choose which websites to cite?
ChatGPT decomposes prompts into sub-queries (query fan-out), sends them to Bing, retrieves and chunks top-ranking pages, then selects the most relevant passages. GPT-5.4 sends 8.5 sub-queries per prompt with domain restrictions; GPT-5.3 sends 1. Selection factors include domain authority, freshness, entity density, and passage-level relevance.
What is query fan-out in AI search?
Query fan-out is when an AI system breaks a user prompt into multiple simultaneous sub-queries and synthesizes findings into one response. Google introduced the term with AI Mode. Your content needs to match the sub-queries, not the original prompt. Ranking for fan-out long-tails often matters more than the head term. Learn how to optimize for AI search.
Do Google rankings affect ChatGPT citations?
Partially. 47% of GPT-5.3's cited domains rank on Google; 44% do not. For GPT-5.4, 75% of cited domains appear in neither Google nor Bing. AI Overviews show the strongest correlation: 76.1% of cited URLs rank in Google's top 10. SEO remains the primary entry for AI Overviews and GPT-5.3; thinking models bypass rankings. More on AI vs. traditional search.
What types of content do LLMs cite most?
For branded queries: reviews and social proof (57%), directories (17%), product pages (12%). For non-branded queries on GPT-5.4: pricing pages (19%), homepages (22%), product pages (10%). Blogs are 32% of GPT-5.3 citations but only 8% on GPT-5.4. The right content type depends on query intent and model.
How often do LLMs hallucinate or misattribute citations?
50-90% of LLM responses are not fully supported by cited sources (SourceCheckup, Nature Communications 2025). Hallucinated citation rates range from 14-95% across 13 models. RAG fixes URL hallucination but not accuracy. Write with specific numbers and named entities to reduce misattribution. Use brand monitoring tools to catch errors.
How can I track whether AI models are citing my website?
Three approaches: manual prompt testing across platforms, GA4 segments for AI referrers (utm_source=chatgpt.com) to measure AI traffic, and dedicated tools like Ahrefs Brand Radar or Otterly.AI. Combine all three since different tools track different dimensions.
Why does ChatGPT cite different sources every time I ask the same question?
Probabilistic models introduce randomness via "temperature" settings. Location, model version, query timing, and phrasing all affect results. Only 27% of fan-out keywords stay consistent across searches; 66% appear only once. 40-60% of cited sources rotate monthly (Semrush). Continuous monitoring is necessary, not one-time audits.





